Appearance
简介
- Scrapy 是一个快速高级的网络爬虫和网络抓取框架,用于爬取网站并从中提取结构化数据。它可用于广泛的用途,从数据挖掘到监控和自动化测试。
- 官方文档:https://docs.scrapy.net.cn/en/latest
安装
bash
pip install scrapy工作流程
一般情况
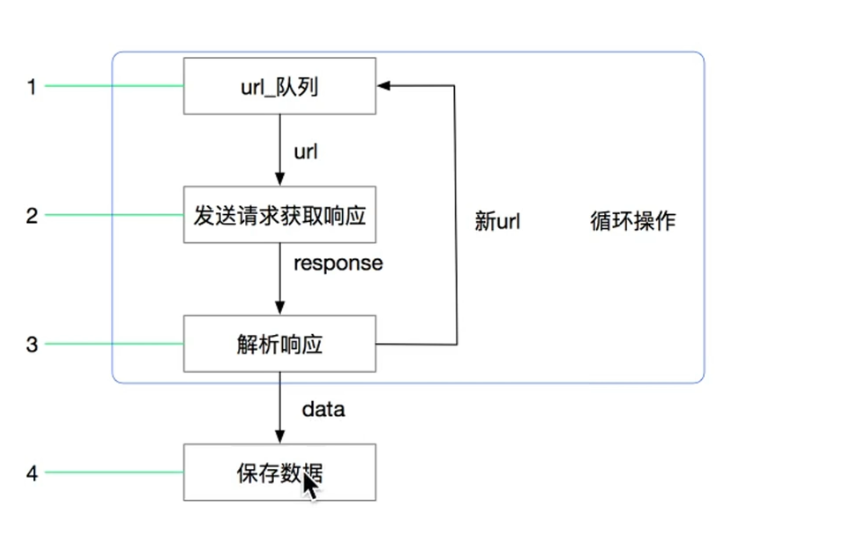
scrapy 工作流程
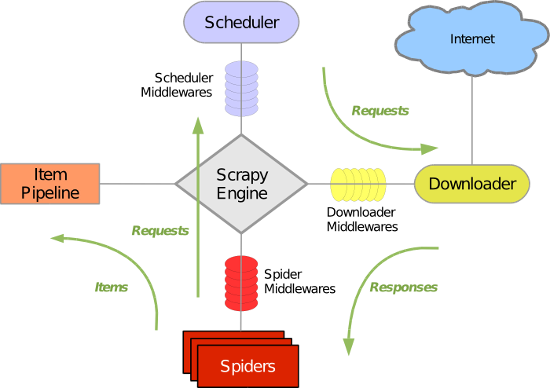
组件
- 引擎(Engine):
- 总指挥:负责数据和信号在不同的模块之间的传递。
- 开发者基本不需要关注,由
scrapy框架处理。
- 调度器(Scheduler):
- 一个队列,存放引擎发过来的请求。
- 开发者基本不需要关注,由
scrapy框架处理。
- 下载器(Downloader):
- 下载吧引擎发过来的请求,下载完后,将响应发送给引擎。
- 开发者基本不需要关注,由
scrapy框架处理。
- 爬虫(Spiders):
- 处理引擎发过来的 response,定义如何提取数据的规则, 进行数据提取。
- 开发者主要工作地方
- 项目管道(Pipeline):
- 负责处理提取到的数据,如存储到数据库或文件中。
- 开发者主要工作地方
- 中间件(Middlewares):
- 用于处理请求和响应,如添加 headers、处理 cookies 等。
- 开发者主要工作地方